

訂閱電子報,掌握最新科技與產業趨勢

2024/01/18
選擇 LPWAN 技術的考量點

2023/10/21
AR/VR 智慧娛樂設備上的低功耗無線連接
2023/09/22
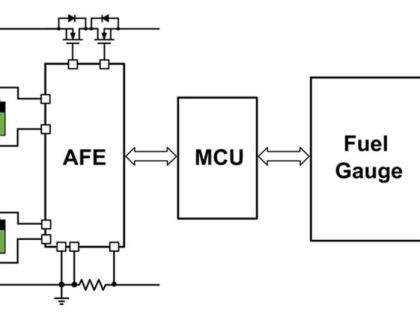
MPS高效能儲能BMS解決方案

2023/07/20
運用 Silicon Labs - Secure Vault™ 保護物聯網安全

2023/04/17
準備好迎接新的藍牙® 5.4 了嗎? - 您應該首先了解什麼

2023/04/06
使用 Enovix 3D 鋰離子電池 解放新產品設計的全部潛力

2023/02/09
值得關注的7大新興藍牙技術趨勢

2023/02/23
雲端伺服器中的 CXL 記憶體擴充與池化

2022/12/16
【成功案例】EFR32BG22助力MOKO M4 Tag產品強化資產 追蹤定位服務

2022/11/04

