

Subscribe to EDOM TECH Newsletter
2026/06/16
Memory Optimization Strategies for Scaling AI Models on NVIDIA Jetson
As edge AI applications continue to evolve, developers are deploying increasingly sophisticated workloads directly on embedded devices—from large language models (LLMs) and vision-language models (VLMs) to multimodal AI assistants and autonomous robotics. While the computational capabilities of the NVIDIA Jetson platform have advanced significantly, memory capacity remains one of the primary constraints when deploying these larger models at the edge.
Unlike traditional GPU servers that feature dedicated graphics memory, Jetson platforms utilize a unified memory architecture in which the CPU and GPU share the same system memory. This design offers excellent efficiency for embedded systems but also makes memory optimization a critical factor in determining which AI workloads can be deployed successfully. By optimizing both the operating system and the AI software stack, developers can reclaim several gigabytes of available memory, enabling larger AI models to run efficiently on resource-constrained edge devices.
Unlike traditional GPU servers that feature dedicated graphics memory, Jetson platforms utilize a unified memory architecture in which the CPU and GPU share the same system memory. This design offers excellent efficiency for embedded systems but also makes memory optimization a critical factor in determining which AI workloads can be deployed successfully. By optimizing both the operating system and the AI software stack, developers can reclaim several gigabytes of available memory, enabling larger AI models to run efficiently on resource-constrained edge devices.
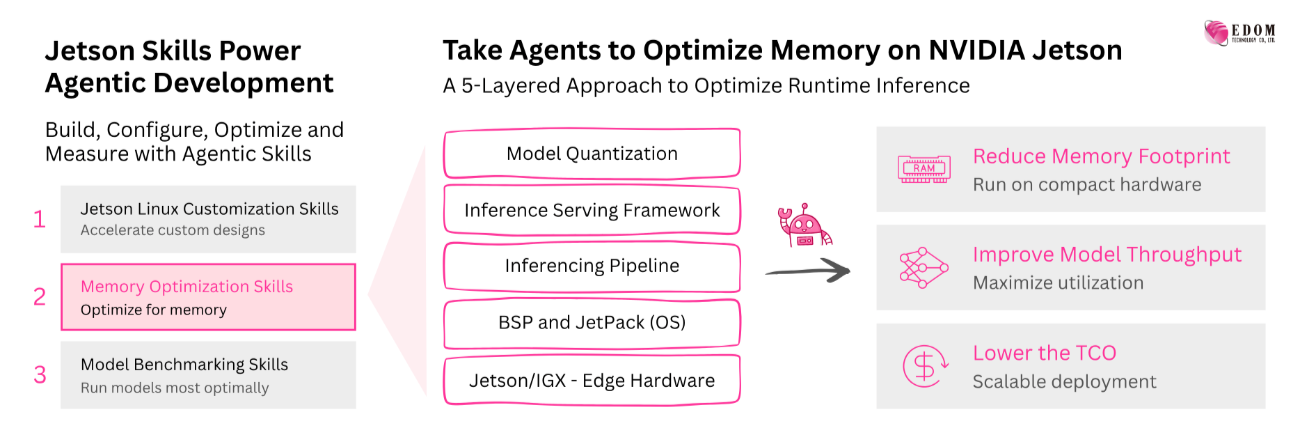
The Five Layers of Memory Optimization
1. Why Memory Optimization Matters
For many edge AI deployments, increasing computational performance alone is not enough. The ability to efficiently utilize available memory often determines whether an application can be deployed successfully.
Memory optimization offers several key benefits:
Memory optimization offers several key benefits:
- Enables deployment of larger LLMs and VLMs on Jetson platforms.
- Improves inference stability by reducing the risk of out-of-memory (OOM) errors.
- Increases overall system responsiveness by minimizing unnecessary background memory usage.
- Creates additional headroom for running multiple AI services simultaneously.
Rather than treating memory as a fixed hardware limitation, developers should view it as a resource that can be optimized throughout the entire deployment pipeline.
2. Start with System-Level Optimization
One of the easiest ways to recover memory is by reducing the operating system's footprint. Since many Jetson devices are deployed as dedicated edge systems without displays or user interfaces, running a full desktop environment is often unnecessary.
Common system-level optimizations include:
Common system-level optimizations include:
- Disabling the graphical desktop environment (GNOME).
- Stopping unnecessary background services such as audio, logging, or unused networking components.
- Reducing reserved system memory where appropriate.
- Monitoring CPU and GPU memory usage with tools such as procrank and NVIDIA NvMap utilities.
Although each adjustment may only save hundreds of megabytes, the combined effect can free a significant amount of memory before AI applications even begin executing.
3. Build Leaner AI Inference Pipelines
Application design also plays an important role in memory efficiency. Small implementation choices can accumulate into meaningful reductions in runtime memory consumption.
Developers can improve efficiency by:
Developers can improve efficiency by:
- Deploying applications directly on the host system instead of inside containers when appropriate.
- Implementing production applications in C++ rather than Python to reduce runtime overhead.
- Disabling visualization components such as on-screen display (OSD) and tiling when running headless inference.
- Removing unnecessary services or modules that are not required during deployment.
These optimizations not only reduce memory usage but also contribute to lower latency and improved overall system performance.
| Optimization | Memory Saved |
|---|---|
| Run bare metal instead of containers | ~70 MB |
| Use C++ instead of Python | ~84 MB |
| Disable visualization components (OSD/Tiler) | ~258 MB |
Total savings can reach approximately 412 MB.
4. Choose an Inference Framework Designed for Edge AI
The inference framework itself has a measurable impact on memory consumption. Different frameworks are optimized for different priorities, including throughput, flexibility, or memory efficiency.
For Jetson deployments:
For Jetson deployments:
- vLLM provides excellent throughput for serving large language models.
- SGLang offers flexible workflows for generative AI applications.
- Llama.cpp is highly memory-efficient, making it well suited for resource-constrained devices.
- TensorRT Edge-LLM is specifically optimized by NVIDIA for edge AI inference on Jetson platforms.
Selecting the appropriate framework should be considered alongside model selection, particularly for deployments where available memory is limited.
5. Quantization: The Most Effective Optimization
Among all software optimization techniques, quantization delivers the greatest reduction in memory usage. By lowering model precision from FP16 or BF16 to formats such as INT4, FP8, or NVIDIA's W4A16, developers can dramatically reduce model size while maintaining high inference accuracy.
Examples:| Model | Before | After | Memory Saved |
|---|---|---|---|
| Qwen3 8B | FP16 | W4A16 | ~10 GB |
| Qwen3 4B | BF16 | INT4 | ~5.6 GB |
The advantages include:
- Several gigabytes of memory savings depending on the model.
- Faster inference performance.
- Lower power consumption.
- Ability to deploy models that would otherwise exceed available memory.
For many edge AI applications, quantization provides the single largest improvement in deployment efficiency and should be considered early in the optimization process.
Remember: Use the lowest precision that still meets your accuracy requirements.
Real-World Example: Reachy Mini Robot
- A vision-language model (Cosmos-Reason2-2B)
- Speech recognition (Whisper)
- Text-to-speech (Kokoro)
- Robot control software
- A web-based user interface
Without memory optimization, the workload exceeded the available system memory. After applying system tuning, selecting optimized inference frameworks, and quantizing the AI models, the complete multimodal application operated using approximately 4.5 GB of the available 7.6 GB system memory, enabling stable, fully local AI execution without cloud dependency.
Quantization First, Framework Second, Hardware Third
As AI models continue to increase in size and complexity, maximizing memory efficiency is becoming just as important as improving computational performance. Successful edge AI deployments require optimization across every layer of the software stack—from the operating system and application architecture to the inference framework and model precision.
By combining system-level tuning with efficient AI frameworks and model quantization, developers can unlock significantly larger workloads on NVIDIA Jetson platforms while maintaining the low power consumption, compact form factor, and real-time responsiveness required for edge computing.
Whether building intelligent robotics, smart vision systems, industrial automation, or generative AI applications, a well-optimized memory strategy enables developers to maximize the full potential of the NVIDIA Jetson platform.
Practical Takeaways for Jetson Developers
If you're deploying LLMs or Vision AI on Jetson:
- Run headless whenever possible.
-
Remove unnecessary OS services.
- Prefer C++ over Python for production pipelines.
- Use memory-efficient frameworks such as Llama.cpp or TensorRT Edge-LLM.
- Quantize aggressively (INT4/W4A16) while maintaining acceptable accuracy.
- Offload vision preprocessing to Jetson's dedicated accelerators (PVA, ISP, NVENC/NVDEC) instead of consuming GPU memory and compute.
Why This Matters
For teams evaluating platforms like NVIDIA Jetson AGX Thor, NVIDIA Jetson Orin NX, NVIDIA Jetson Orin Nano, or even comparing them with DGX-class systems, the article reinforces that memory optimization often delivers larger gains than simply buying more hardware. With proper quantization and runtime choices, Jetson devices can run models that would otherwise exceed their memory limits, making sophisticated edge AI applications feasible without cloud infrastructure.
For your work around Jetson Thor and DGX Spark, "Quantization first, framework second, hardware third." Memory reduction from INT4/W4A16 quantization can be measured in gigabytes, far exceeding the gains from most other software optimizations.
Kickstart Your Edge Development Today
-

Get Your Jetson
The NVIDIA Jetson modules deliver accelerated compute for any automation scenario—whether in manufacturing, construction, healthcare, or logistics—offering unmatched performance, power efficiency, and ease of development. -
Our Certified Peripheral Solutions
Our validated ecosystem integrates cameras, sensors, storage, and high-speed I/O for NVIDIA Jetson, accelerating edge AI deployment across robotics, vision, and industrial applications. -

Fine-Tune LLMs on Jetson
Learn how to fine-tune large language models directly on Jetson using PyTorch and Hugging Face TRL. Covers Full SFT (4B), LoRA (9B), and QLoRA (27B).
Source: This article is based on the NVIDIA technical blog "Maximizing Memory Efficiency to Run Bigger Models on NVIDIA Jetson" by Anshuman Bhat and Aditya Sahuand published on April 20, 2026, and has been adapted with additional technical interpretation for developers building AI solutions at the edge.

